
热门主题




PaddlePaddle平台对抗样本工具包Advbox
2018-02-26 16:19:5614417人阅读
作者:姜辉,郭星,高磊,韦韬
摘要
对抗样本广泛存在于深度神经网络中,其表现出来的显著反直观特点吸引了越来越多的研究者进入对抗样本检测、生成与防御研究领域。对抗样本工具包能够为研究者深入开展研究提供极大的便利,免去重复“造轮子”的精力与时间消耗,可以高效地使用最新的生成方法构造对抗样本数据集用于对抗样本的特征统计、攻击全新的AI应用抑或是加固业务AI模型。目前大部分主流的机器学习平台/框架均已有相应的对抗样本工具包,如Tensorflow平台的cleverhans等。我们为PaddlePaddle平台贡献了对抗样本工具包Advbox,便于平台的开发者、使用者等参与者能够更好地发现和降低模型健壮性的风险敞口。相较于cleverhans,Advbox在代码结构、易用性和参数调优上都更有优势。我们期待有更多开发者和研究者加入到PaddlePaddle平台中来,共同丰富和完善PaddlePaddle平台的安全生态,也欢迎贡献自己最新的对抗样本检测、生成或防护算法,验证评估后我们也会及时更新至Advbox中。
1. 背景
深度神经网络(DNNs)已经成为近几年来最为炙手可热和引人瞩目的人工智能(AI)学习模型。在图像分类等具体识别、分类任务上,深度神经网络都表现出能够与人类相媲美,甚至于远超人类的模式识别和分类能力。然而最近的研究表明深度神经网络自身非常容易受到对抗样本(adversarial example)的攻击,攻击者可以在正常数据输入的基础上精心构造足够小的扰动,生成对抗样本。对抗样本在难以被肉眼或者常用统计方法所检测到的同时,能够导致AI模型以较高的置信度输出错误的分类(non-targeted attack),或者错误分类为攻击者指定的目标类别(targeted attack)。
对抗样本的数学定义可表述为,我们将模型的得分函数(scorefunction)表示为![]()
,对于给定的输入x,假设为y类,我们简单地表示为![]() 。在原输入x的基础上施加很小的扰动
。在原输入x的基础上施加很小的扰动![]() ,即
,即![]() 。对于非指定目标攻击
。对于非指定目标攻击![]() ,对抗样本让原输入x对应的y类得分下降而使其它类得分超过y类得分;对于指定目标攻击
,对抗样本让原输入x对应的y类得分下降而使其它类得分超过y类得分;对于指定目标攻击![]() ,对抗样本将使目标的得分超过其它类别(包括y类)。
,对抗样本将使目标的得分超过其它类别(包括y类)。
对抗样本的存在,将威胁深度神经网络在实际业务和物理场景中的应用。具体的例子如图1-1所示:

图1-1 对抗样本生成示意图
inception v3[1]模型将左侧图片识别山地车,通过加入肉眼无法区分的扰动构成对抗样本(右侧的图片),被inception v3模型以高置信度识别成蟑螂。
对抗样本在多种机器学习、深度学习模型广泛存在。并且对抗样本存在显著的迁移特性,即同一模型(白盒)的不同实例间(不同的超参数)可以使用对抗样本进行迁移,不同模型(黑盒)间同样能够被对抗样本迁移攻击。
为了方便对抗样本的研究以及利用生成的对抗样本加固模型,目前主流的机器学习平台都提供了对抗样本生成的工具包,如Tensorflow的cleverhans[9]。本文主要介绍PaddlePaddle平台的对抗样本工具包Advbox,与cleverhans相比使用更加简洁,并且攻击成功率方面也有明显优势。目前Advbox已经在github[2]上随PaddlePaddle一起开源,欢迎更多朋友贡献算法。
2. 工具包Advbox
我们在百度深度学习平台PaddlePaddle上开发了对抗样本工具包Advbox[2],并成为PaddlePaddle平台中的重要安全工具。Advbox的目的有三个:第一,作为测试深度学习模型抵御对抗样本的健壮性的基准。第二,通过生成的对抗样本加固现有的模型(对抗训练)。第三,作为对抗样本研究的工具包。
目前,Advbox实现了多种生成对抗样本的攻击方法,包括
FGSM[3] (Explaining and Harnessing Adversarial ExamplesBy Goodfellow et al.),BIM[4] (Adversarialexamples in the physical world by Alexey Kurakin et al.), DeepFool[5] (DeepFool: a simple and accuratemethod to fool deep neural networks by Seyed-Mohsen Moosavi-Dezfooliet al.),同时还有JSMA[7](The Limitations of DeepLearning in Adversarial Settings by NicolasPapernot et al.)
。其中JSMA,FGSM,BIM同时实现了包括误分类non-targeted攻击和指定目标的targeted攻击。下面是相关算法的介绍以及Advbox工具包的使用。
2.1 相关算法介绍
2.1.1 FGSM算法
FGSM由Goodfellow等研究者于2015年提出,他们试图从AI模型的线性角度解释对抗样本存在的原因。假设线性模型权重参数为w,输入为n,扰动为δ,则新的输出为![]() 。这样一来,激活函数输入就相较原始输入增加了
。这样一来,激活函数输入就相较原始输入增加了![]() 。如果权重w的量级为m,其维度为n,扰动最大值为ε,那么对抗样本对激活函数造成的影响即为
。如果权重w的量级为m,其维度为n,扰动最大值为ε,那么对抗样本对激活函数造成的影响即为![]() ,随着维度n的增加,扰动给激活函数输入带来的增量也相应增大,最终将会改变激活函数的输出值。
,随着维度n的增加,扰动给激活函数输入带来的增量也相应增大,最终将会改变激活函数的输出值。
作者认为目前大部分深度神经网络的激活函数都采用ReLU而不再是sigmoid函数,越来越多的线性被引入导致了对抗样本的存在。基于这一假设,作者提出了FGSM用于生成对抗样本,采用Linfinity作为范数约束,对于非指定目标攻击,其构造目标函数为;对于指定目标攻击,目标函数变化为。直观上来看,损失函数对于输入x的梯度是损失函数变化最快的方向。在非指定目标攻击场景下,沿着梯度方向增加像素值将会使得原始类别标签的损失值增大,从而降低模型判定对抗样本为原始类别的概率;在指定目标攻击场景下,沿着梯度相反方向增加像素值将会使得指定目标类别标签的损失值减小,从而增加模型判定对抗样本为指定目标类别的概率。
同时在论文中,作者还首次揭示了对抗样本的分布特征,即对抗样本往往存在于模型决策边界的附近,在线性搜索范围内,模型的正常分类区域和被对抗样本攻击的区域都仅占分布范围的较小一部分,剩余部分为垃圾类别(rubbish class),如图2-1所示。
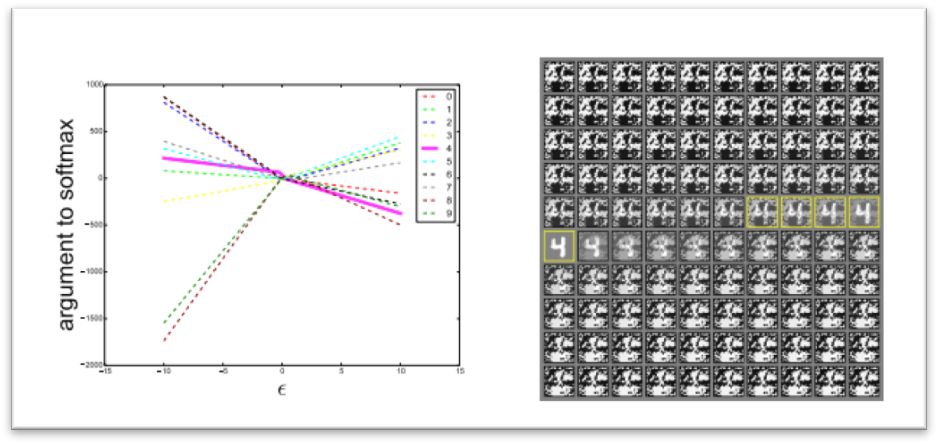
图2-1 对抗样本的分布
左图展示了在一张输入样本上变化ε,mnist10个类别每个类别对应softmax层参数的变化。这张图片的正确类别是4。右图是生成曲线的输入,黄色框中表明了正确分类的输入,黄色框左上角对应负ε,右下角对应正ε。每个类别对应的非规范化的对数概率明显与ε分段线性相关,而且在广泛的ε范围内错误的分类比较稳定。
2.1.2 BIM算法
2017年Google Brain的Kurakin等研究者在FGSM的基础上提出了BIM用于快速生成对抗样本。BIM实际上是一个迭代版的FGSM,同样采用Linfinity作为范数约束。
对于非指定目标攻击,作者在每次迭代中使用FGSM生成对抗样本,并加入clip函数用于图片归一化的值域回归,即:\
![]()
对于指定目标攻击,作者在迭代中采用类似的方法,即:
![]()
在实际生成对抗样本的过程中,作者建议值α为1。直观上,BIM与FGSM一样方便理解,同时简洁高效,攻击效果显著优于FGSM。后续有很多BIM的变种[6],都有着不俗的攻击效果。
不过后续研究表明,基于迭代的方法有相对较差的迁移性,使得进行黑盒攻击的效果变差。而只有一步的基于梯度的方法虽然白盒攻击的效果不好,但是能产生更具迁移性的对抗样本。
2.1.3 DeepFool算法
DeepFool[4]由EPFL的Moosavi-Dezfooli等研究者于2015年提出,收录于2016年CVPR会议中。作为一种白盒对抗样本生成方法,DeepFool原理上由二分类模型出发,计算最小扰动距离为当前输入点到分割超平面的最短距离,推导出二分类任务下的扰动生成方法,并从二分类推广至多分类。DeepFool使用L2范数约束,对抗样本生成效果优于FGSM与JSMA方法,在当时是比较先进的攻击方法。
2.1.4 JSMA算法
2016年Papernot等研究者基于L0的范数约束,提出了指定目标攻击的JSMA[7]方法用于生成对抗样本。JSMA旨在尽可能减少需要改变的像素点,目标是找到整幅图片中对指定目标具有利的最大显著性像素点,通过改变该像素值的大小,实现基于单像素点的对抗样本生成。作者构造了显著性列表(saliency map)用于搜索最佳像素点,如公式2-1所示,当像素点对指定目标类别的偏导数小于0时,增加该像素点的像素值将导致指定目标类别的得分函数值降低;当该像素点对其它类别的偏导数和大于0时,增加该像素点的像素值将导致其它类别的得分函数值增大,等价于降低了指定目标类别的得分函数值。这样的像素点对指定目标不利,不属于最佳像素点。相反,当像素点对指定目标类别的偏导数大于0或者对其它类别的偏导数和小于0时,增加该像素点的像素值将有利于模型判定为指定目标类别,显著性最大的像素点即为JSMA所要搜索的像素点。在实际的对抗样本生成中,由于单像素点的约束过强,作者建议放宽至两个像素点对的生成上,如公式2-2所示。
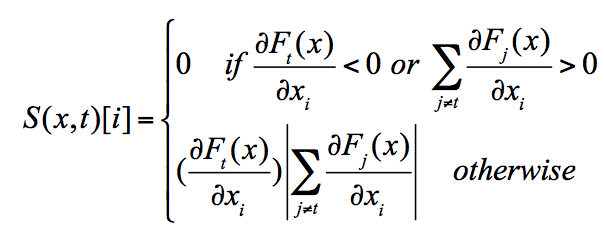
公式2-1 JSMA显著性列表计算公式
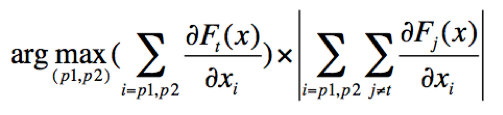
公式2-2 像素点对的显著性列表计算公式
作者在MNIST数据集上使用JSMA生成了对抗样本,如图2-2所示。我们可以看到,对角线上的图片为原始图片,在L0的范数约束下,肉眼较容易地区分对抗样本与原始图片的差别。
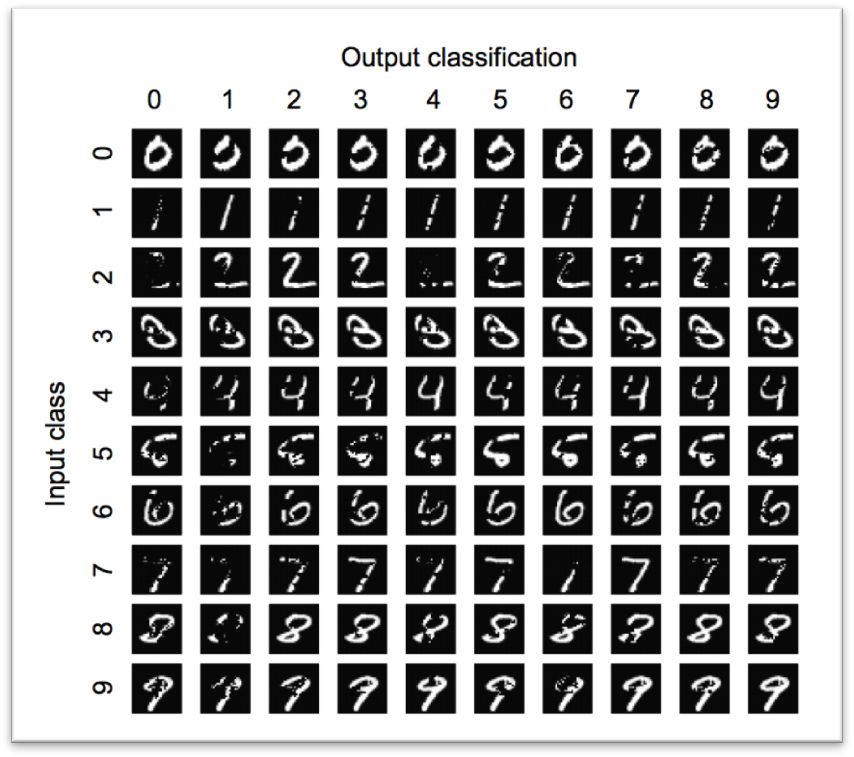
图2-2 JSMA在MNIST数据集上生成的对抗样本
2.2 Advbox核心功能
Advbox主要分成一下几个模块:
Attack:attack class定义了攻击方法的接口,后面所有攻击方法都继承Attack基类,实现相应的接口。
Model:model class表示深度学习的模型,定义了模型相关的接口。
Adversary:adversary class包含初始图像,以及生成的untargeted或者targeted对抗样本。
2.3 攻击步骤
Advbox目前实现的方法都是基于白盒的攻击。下面以mnist举例,
1、首先要训练一个模型并保存模型参数。
fluid.io.save_params(exe,"./mnist/", main_program=fluid.default_main_program())
2、然后加载模型的参数还原模型。
fluid.io.load_params(exe,"./mnist/", main_program=fluid.default_main_program())
3、利用还原的模型,构造一个PaddleModel对象。
m= PaddleModel(fluid.default_main_program(), IMG_NAME, LABEL_NAME,
logits.name, avg_cost.name, (-1,1))
4、选择一种攻击方法,比如GradientSignAttack(FGSM),将PaddleModel作为参数传给GradientSignAttack。
att= GradientSignAttack(m)
5、把image和label作为参数传入4中的attack对象中,则进行攻击,生成对抗样本保存在返回值Adversary中。
adversary= att(Adversary(data[0][0], data[0][1]))
2.4 测试结果
我们在mnist数据集上训练了简单的cnn模型,训练的准确率达到了98%。然后在此模型上进行了untargeted攻击,选取了mnist的测试集10000张图片。分别使用了FGSM和BIM进行攻击,攻击成功率分别达到了97.6%和99.98%。
2.5 与cleverhans对比
Advbox基于Paddle最新的Fluid[8]开发,与Tensorflow中的cleverhans[9]库主要有以下两点优势:
1、使用的简洁性。cleverhans的攻击方法使用之前,需要先在攻击模型上继承cleverhans.model中的Model类,而使用Advbox攻击的时候只需要把攻击模型的program作为参数传给攻击类即可。Advbox相对于cleverhans使用起来简单很多。
2、攻击成功率的优势。cleverhans中的迭代的攻击方法均使用了固定的步长eps,一方面步长eps的设定对使用者而言需要一定的经验和技巧,另外一方面eps的值影响着攻击的成功率,eps过高会导致对抗样本的修改肉眼看上去过与明显,而eps设置低的话会导致攻击的成功率降低。因此在adversary库中针对这一点进行了改进,eps中的值的设置采取了从小到大进行迭代的方式,一方面能提高攻击的成功率,另外一方面能保证对抗样本的修改不显得过于明显,在攻击成功率和对抗样本的修改之间取得一个平衡。
3. 总结
Advbox是Paddle上一个开源的对抗样本工具集,你不仅可以利用Advbox生成对样样本,测试模型的健壮性,还可以利用Advbox生成对抗样本来加固你的模型。目前Advbox支持FGSM,BIM,JSMA和DeepFool等方法,后续将会有更多的攻击方法(如L-BFGS[10], Carlini/Wagner[11])加入。Advbox已经成为PaddlePaddle平台上重要的安全工具,欢迎大家参与Paddlepaddle以及Advbox的工作。更多精彩内容请关注实验室的公众号。
Advbox的github地址如下:
https://github.com/PaddlePaddle/models/tree/develop/fluid/adversarial
4. 参考资料
[1] ChristianSzegedy, VincentVanhoucke, Sergey Ioffe,et al. Rethinking the Inception Architecture for Computer Vision, 2015.
[2] https://github.com/PaddlePaddle/models/tree/develop/fluid/adversarial
[3]Ian J.Goodfellow,JonathonShlens, ChristianSzegedy. Explaining and Harnessing Adversarial Examples, 2014.
[4] AlexeyKurakin, IanGoodfellow, Samy Bengio.Adversarial examples in the physical world, 2016.
[5]Seyed-MohsenMoosavi-Dezfooli,AlhusseinFawzi, PascalFrossard. DeepFool: a simple and accurate method to fool deep neuralnetworks, 2015.
[6]Yinpeng Dong, Fangzhou Liao, Tianyu Pang,et al. Boosting Adversarial Attacks with Momentum, 2017.
[7] NicolasPapernot, PatrickMcDaniel, Somesh Jha,et al. The Limitations of Deep Learning in Adversarial Settings,2015.
[8] http://staging.paddlepaddle.org/docs/develop/documentation/en/design/fluid.html
[9] https://github.com/tensorflow/cleverhans
[10] Pedro Tabacof, Eduardo Valle.Exploring the Space of Adversarial Images, 2015
[11] NicholasCarlini, David Wagner.Towards Evaluating the Robustness of Neural Networks, 2017
本文来自百度安全实验室,作者:姜辉,郭星,高磊,韦韬,百度安全经授权发布
文章图片来源于网络,如有问题请联系我们