
-
史宾格安全及隐私合规平台3分钟完成一周工作量 更快实现隐私合规
-
IP信誉查询多因子计算,多维度画像
-
智能数据安全网关为企业数据安全治理提供一体化数据安全解决方案
-
4网址安全检测
-
5SMS短信内容安全
-
6百度漏洞扫描
-
7爬虫流量识别
-
8百度AI多人体温检测
-
9工业大脑解决方案
-
10APP安全解决方案
-
11企业人员安全意识解决方案
-
12安全OTA
-
13大模型安全解决方案
-
14安全知识图谱
-
15智能安全运营中心AISOC
热门主题




安全攸关场景下AI的挑战和应对—深度学习模型鲁棒性研究综述及Perceptron评测工具发布
2019-06-11 18:10:0824988人阅读
0x01 深度学习鲁棒性研究现状
深度神经网络在众多重要的视觉任务中取得了令人印象深刻的成果,比如在图像分类任务上已经达到了超越人类的准确性。然而与人类视觉系统相比,深度学习视觉模型出人意料的在对不同于训练分布的,仅仅添加了很小的扰动的样本上预测效果不佳。这些被称为“对抗样本(adversarial example)” 的输入的存在,为深度学习在许多安全关键性的场景中的应用如自动驾驶,人脸识别,恶意软件检测等带来了威胁与不确定性。
如图1所示,我们发现即使是在黑盒条件下生成的对抗样本,也可以有效的欺骗 Google Cloud Vision 平台的不同API,如图像识别,目标检测,色情识别,以及文字识别等众多基于深度学习的视觉应用。通过极少的访问数量即可造成云端黑盒模型的绕过,我们在Blackhat Asia 2019上做了演示。对抗样本的出现,及其对深度学习模型预测的几乎100%的绕过率,使得深度学习模型在安全攸关(Safety-Critical)场景中的应用面临着严峻的挑战。目前业界通常把深度学习模型抵抗输入扰动并给出正确判断的能力称为鲁棒性。

图1:黑盒生成的对样本可以有效欺骗Google Could Vision四种视觉任务API (Jia et al [1])
我们同时发现,即使在没有对抗攻击的情况下,许多人工智能系统,如无人车的功能安全(safety)仍然很大程度上依赖于其中深度学习模型的鲁棒性。如图2所示,正常情况下能够被目标检测模型YOLO3 识别出的物体,在一个略微不同的光照环境下便无法识别出目标,从而导致潜在的安全隐患。在物理世界里,除了对抗样本,类似光照这样的不确定的环境变化也同样成为了深度学习模型实际存在的威胁,我们的相关研究在Blackhat Europe 2018上进行了展示。对于深度学习鲁棒性在安全攸关的场景下的影响因素,以及现实场景中的应对策略,我们在《深度学习模型鲁棒性研究综述及安全攸关场景下的挑战和应对》,这篇综述文章中进行了详细的总结,点击下方阅读原文即可获得。

图2:原图(左)中能检测到的物体在亮度提升13%之后(右)无法被检测
AI模型安全威胁的多样性使得对生产线上的AI模型鲁棒性评估尤为必要。深度学习模型的鲁棒性正在成为和准确性同样重要的模型评价标准,然而目前业界却缺少这样标准化的鲁棒性测试benchmark,大多已有的对抗机器学习库如Cleverhans [2],IBM Art[3] 都只关注于对抗样本的生成技术,而无法对模型的鲁棒性进行评价,或对其鲁棒性的上下界进行估计。而目前的鲁棒性评估,大多是围绕L_p范式扰动的基于理论的衡量。德国的Tubingen大学提出的Robust Vision Benchmark提供了公共的自动化平台,该平台聚集了各种已知的对抗攻击算法,为大部分开源的深度学习模型以及用户训练好后并上传的模型打分。
仅使用目前开源的对抗机器学习工具无法回答许多关系到深度学习应用前景的重要问题如:
模型 A 是否比模型 B 更加鲁棒?
我使用对抗样本重新训练了我的模型,我的模型鲁棒性是否真正得到了提升? 提升了多少?
我的模型能否得到某种鲁棒性的保证?即当扰动的大小小于某个值时,我的模型能确保预测结果的稳定
0x02: Perceptron Robustness Benchmark 特点介绍
为帮助模型的开发者回答上述问题,百度安全实验室推出了开源的模型鲁棒性基准测试工具:Perceptron Robustness Benchmark(https://github.com/advboxes/perceptron-benchmark)。它不仅对模型多达15种对抗安全(security)和功能安全(safety)的指标提供了标准化的度量,更是在其中一些指标中,为模型提供了可验证的鲁棒性下界。相比于其它对抗机器学习库,Perceptron Benchmark 具有以下特点:
多平台支持:鲁棒性测试代码可以无需修改地对多种热门深度学习框架下的模型进行benchmarking,支持的框架包括:Tensoflow,Keras, PyTorch, PaddlePaddle.
多任务支持:目前所有的对抗机器学习库都仅支持基础的图像分类任务,Perceptron 支持包括对无人驾驶意义重大的目标检测模型在内的多种视觉任务。
云端黑盒模型支持:Perceptron 同时也支持对 MLaaS 场景下封装后的云端模型API的鲁棒性度量,我们为包括Google Cloud Vision, Baidu AIP, Amazon Rekognition在内的多个商用AI平台提供了便于测试的接口。
标准化度量:Perceptron Robustness Benchmark 所给出的模型鲁棒性度量可以用来进行多任务,多模型间的比较,并可被用来作为对模型鲁棒性上界的估计。
可验证的鲁棒性: Perceptron Robustness Benchmark 使用形式化验证的方法,通过符号区间分析 (symbolic interval analysis) 为模型计算出可信赖的鲁棒性下界,即当叠加在样本上的扰动小于该下界,模型能够确保预测结果的一致性。
0x03:使用 Perceptron Robustness Benchmark
示例1:对像素级别扰动的鲁棒性评估
我们为 Perceptron Robustness Benchmark 同时提供了命令行与API两种接口,比如,运行以下命令行即可度量 Keras 框架下的Resnet-50 模型对于C&W[4] pixel-wise 扰动的鲁棒性。

运行结果不仅包含了使用 C&W 方法找到的使用最小的L2 扰动的对抗样本,也包括了对模型在pixel-wise 扰动下鲁棒性上界的估计(2.10e^-07)

图3:pixel-wise扰动鲁棒性度量结果
输出结果如下:

图4:Perceptron 展示出实验找到的使模型出错所需的最小扰动
给出的鲁棒性上界可以被看做是:实验发现的能够使模型出错的所需添加的最小扰动。 Perceptron 同时使用 Symbolic Interval Analysis (Wang et al) 寻找鲁棒性的下界:即形式化验证所得出的能够使模型出错的所需添加的最小扰动。这两个值与真实的模型鲁棒性边界的关系如图4所示。Perceptron 通过寻找更小的鲁棒性上界,与提升可验证的鲁棒性下界的,从两个方向逼近真实的目标模型鲁棒性边界。
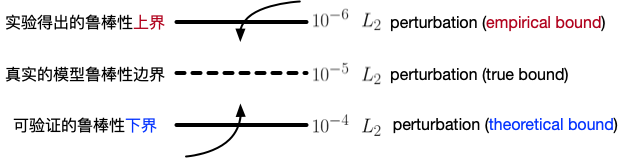
图5:Perceptron 通过提升对鲁棒性的上界下界的度量,来逼近真实的模型鲁棒性
示例2:对光照变换的鲁棒性验证
运行如下的命令行即可测量Pytorch框架下的Resnet-18对于不同光照亮度的鲁棒性,通过在命令行加入“-verify” 参数可使 perceptron 给出可验证的鲁棒性边界。

图6: Perceptron 对亮度变化鲁棒性的验证结果
如图所示,使用像素点乘以亮度系数的方法来模拟光照,perceptron 给出了可验证的光照变换范围 (2.064 ~0.085), 确保当亮度在该范围内变化时模型的预测结果是稳定的。

图7:Perceptron展示验证得到的使模型出错所需最小亮度变化的样本
通过发表AdvBox Perceptron Robustness Benchmark,我们希望将模型的鲁棒性度量标准化,并推动其成为与模型准确性同等重要的模型评价指标。
0x04:结论
越来越多的研究证明,AI的生态面临对抗攻击严峻的挑战,在日益普及的视觉、声音、自然语言模型都会对特定的对抗输入样本给出错误的预测或分类。我们将针对深度学习模型鲁棒性的最新研究成果汇成一篇的综述,涉及各个具有代表性的业务场景在不同对抗样本攻击/正常的环境扰动时所面临的严重风险、现有的模型鲁棒性的度量方法,以及提升模型鲁棒性的手段。此外,我们也在综述中介绍百度安全实验室在AI安全研究前沿的研究成果,包括物理世界与云端黑盒的AI模型攻击与检测,模型鲁棒性度量与提升等等。
我们希望通过这一篇对深度学习模型鲁棒性的综述,剖析其重要性,以及它带来的挑战,为研究人员提供一个铺路石。作为安全从业者,我们认为在安全攸关场景下,模型鲁棒性和模型准确性同等重要,并呼吁整个业界把鲁棒性作为评估模型除了准确性之外的一个新的维度,同时把模型鲁棒性评估标准化。
AdvBox Perceptron Robustness Benchmark 项目主页:https://github.com/advboxes/perceptron-benchmark
[1] Enhancing Cross-task Transferability ofAdversarial Examples with Dispersion Reduction.
https://arxiv.org/abs/1905.03333
[2] Cleverhans: http://www.cleverhans.io/
[3] IBM Art: https://github.com/IBM/adversarial-robustness-toolbox
[4] Towards Evaluating the Robustness of NeuralNetworks. https://arxiv.org/abs/1608.04644
[5] Efficient Formal Safety Analysis of NeuralNetworks. https://arxiv.org/abs/1809.08098