产品人气榜
-
史宾格安全及隐私合规平台3分钟完成一周工作量 更快实现隐私合规
-
IP信誉查询多因子计算,多维度画像
-
智能数据安全网关为企业数据安全治理提供一体化数据安全解决方案
-
4网址安全检测
-
5SMS短信内容安全
-
6百度漏洞扫描
-
7爬虫流量识别
-
8百度AI多人体温检测
-
9工业大脑解决方案
-
10APP安全解决方案
-
11企业人员安全意识解决方案
-
12安全OTA
-
13大模型安全解决方案
-
14安全知识图谱
-
15智能安全运营中心AISOC
热门主题




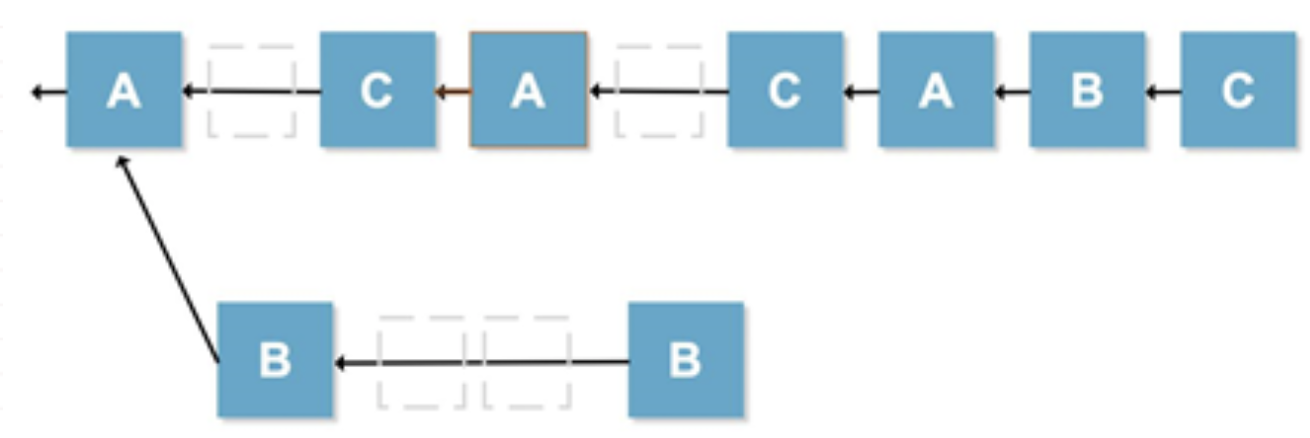
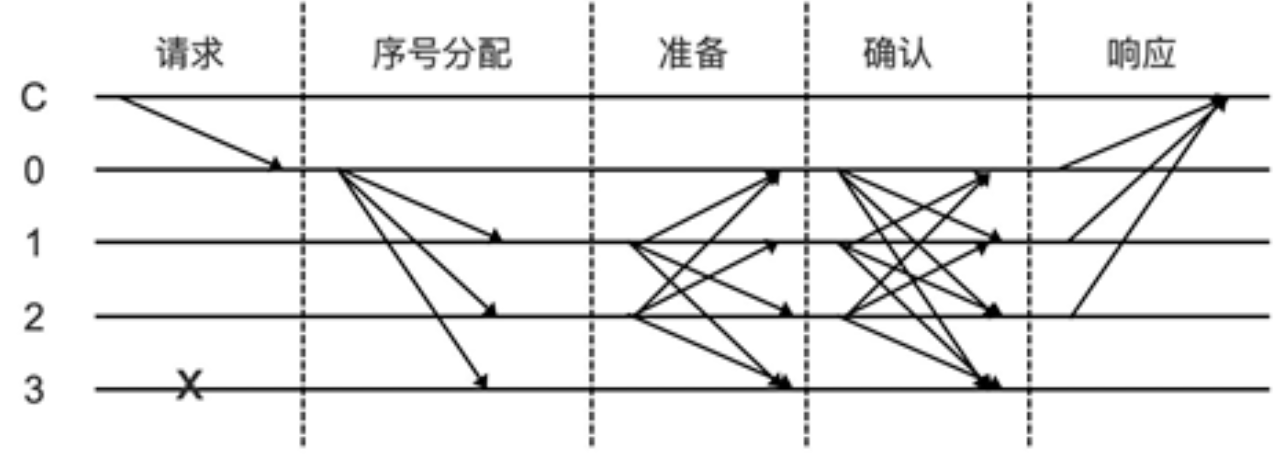
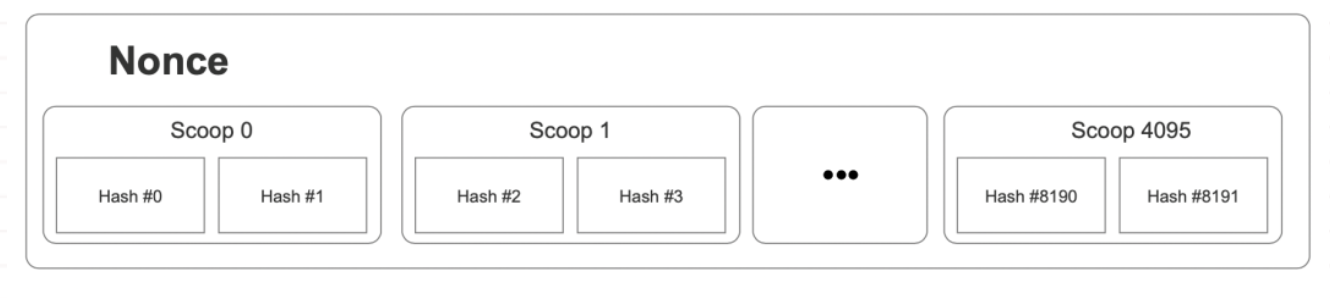
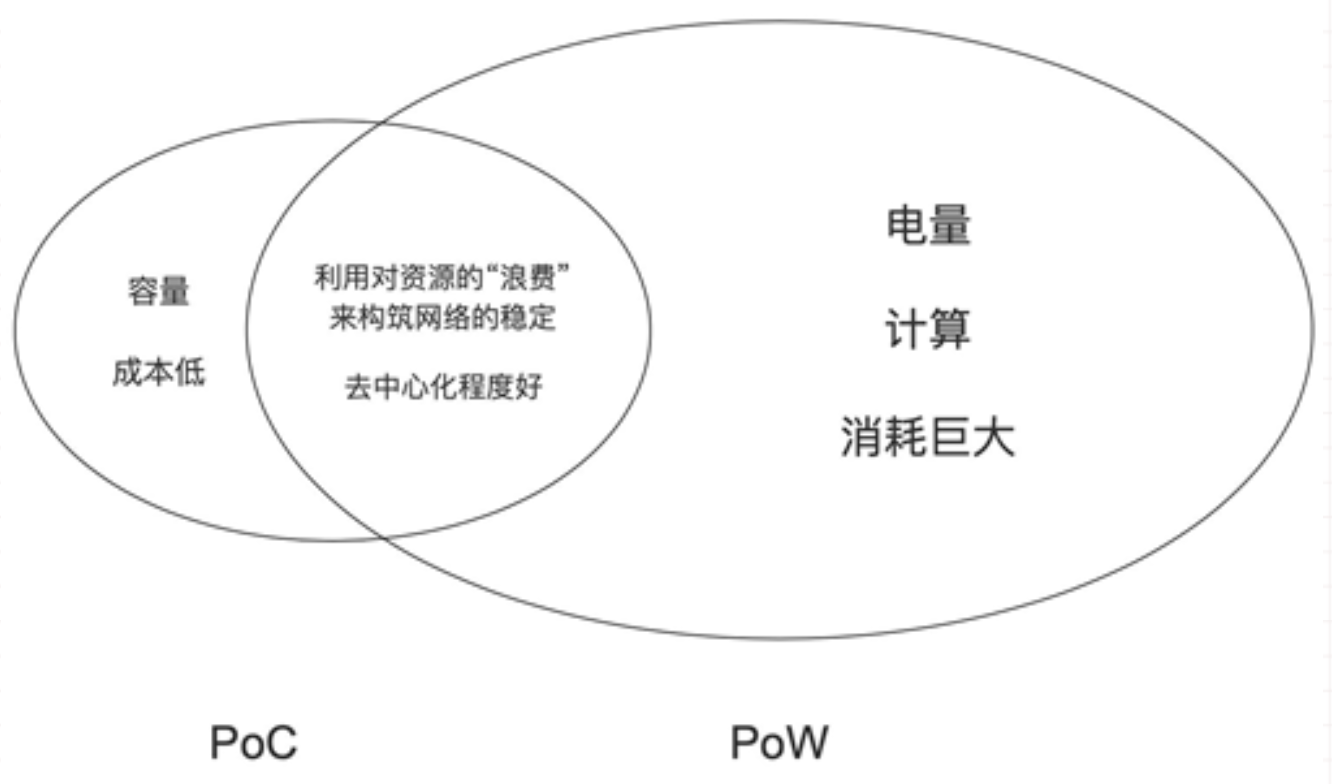
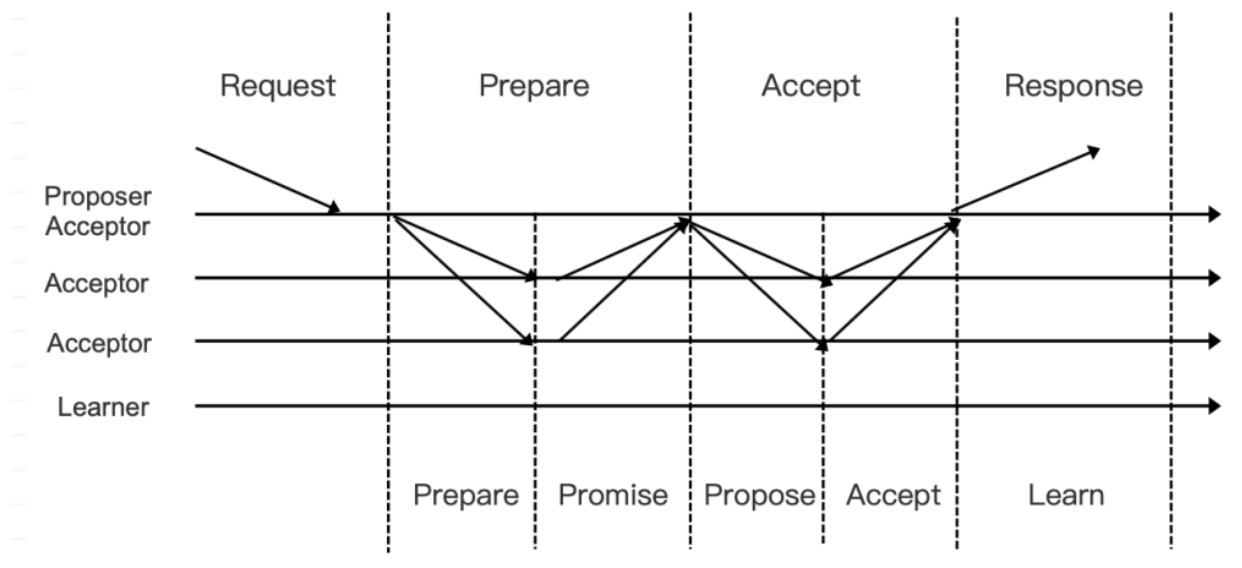
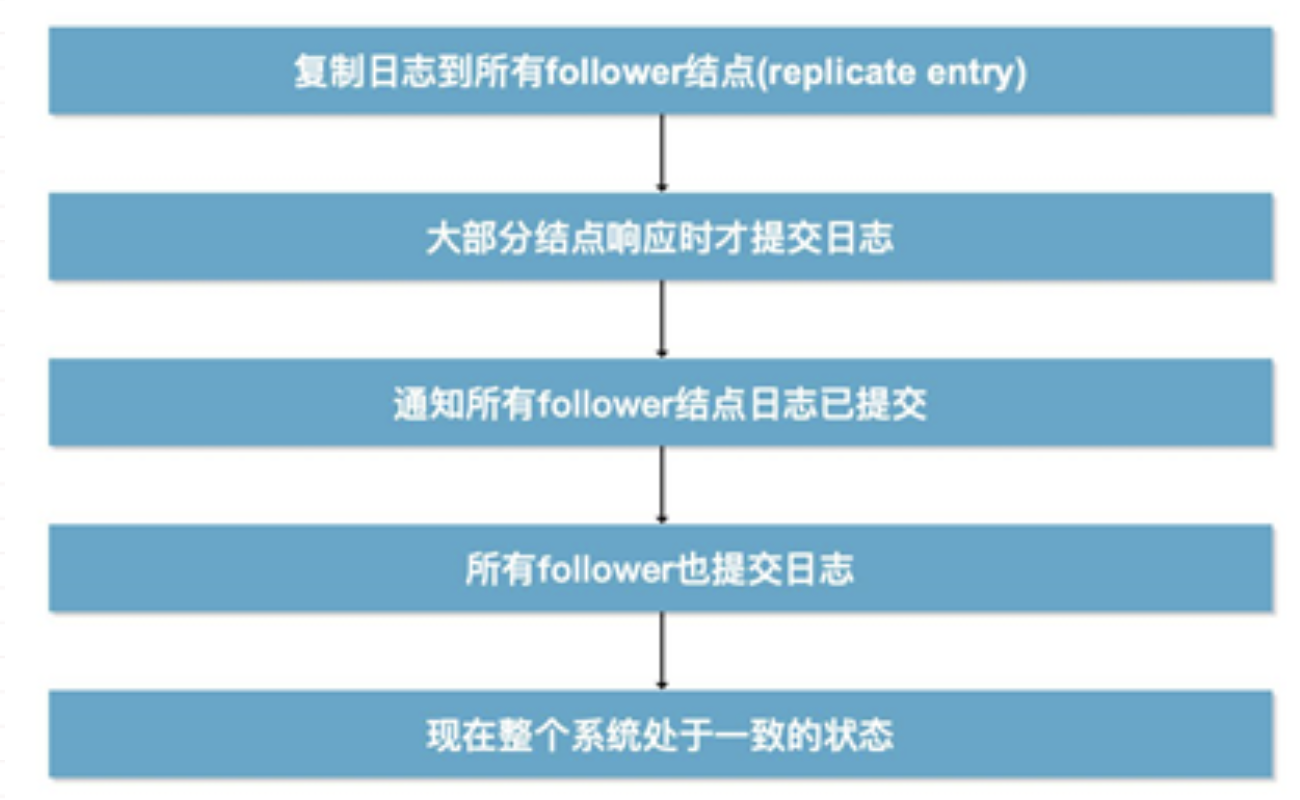
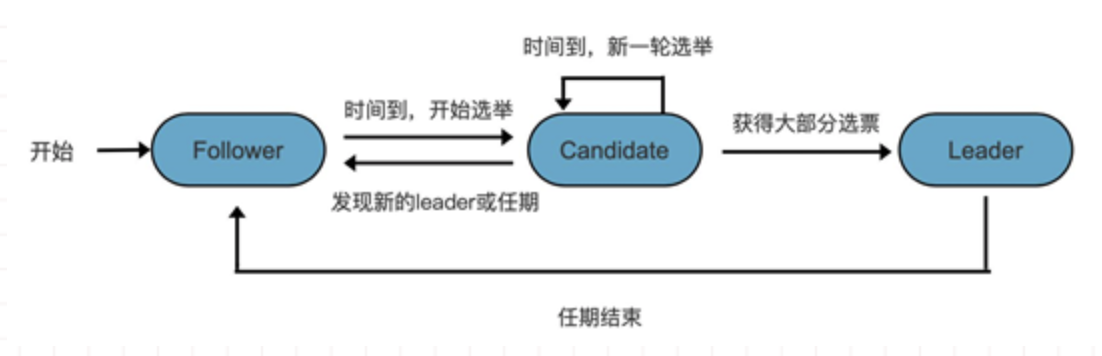
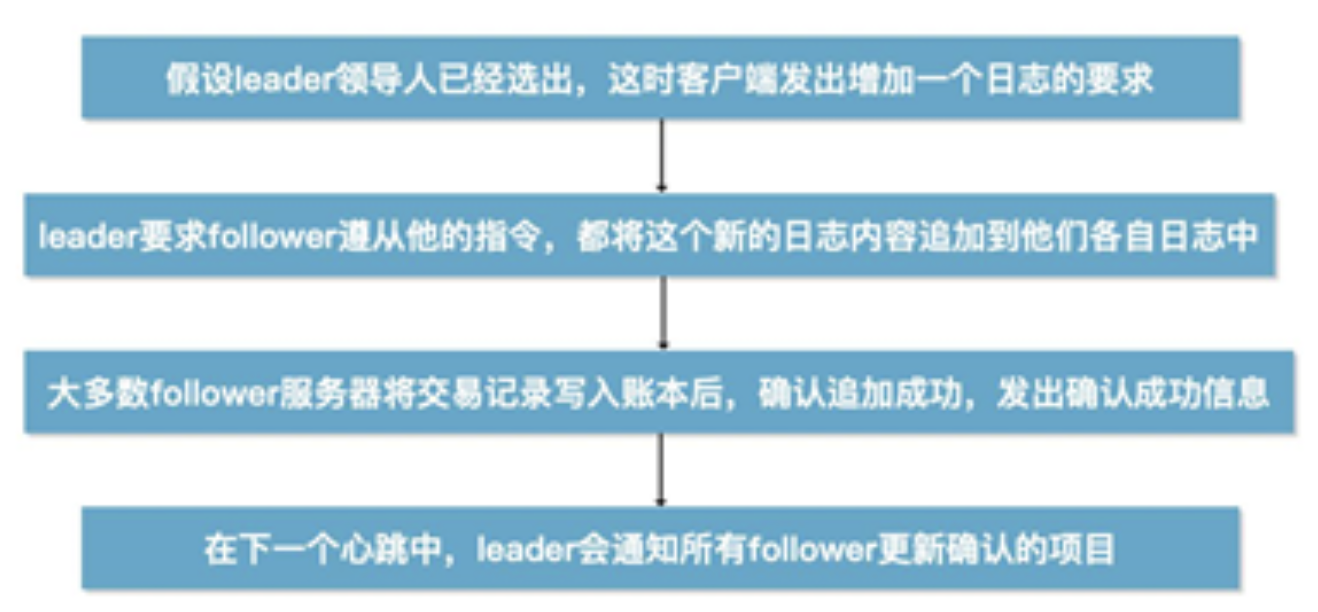
区块链共识机制介绍
2020-06-30 16:51:2227032人阅读